T1.stack - Embedded 시스템의 Stack 사이즈 관리
< Stack overflow를 방지하기 위한 최대 Stack 사용량 분석 >
목차
Stack이란…
Stack은 CPU가 프로그램을 실행하는 동안에 데이터를 저장하는 RAM영역중 하나로, 가장 나중에 입력된 데이터가 가장 먼저 출력되는
“LIFO(Last In, First Out)” 방식으로 동작한다. 일반적으로 함수 내에서 사용하는 데이터는 함수 호출시에 스택에 저장되고, 함수 종료시에
반환된다. 즉, Stack에 저장되는 데이터의 수명은 해당 코드블록이 실행되는 지속시간으로 볼 수 있다. Stack메모리는 다음과 같은 데이터를
저장 할 수 있다.
- 지역 변수
- 리턴 주소
- 함수 인자
- 컴파일러의 임시 변수
- Context 정보
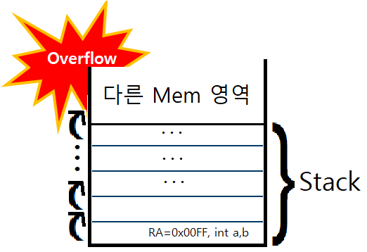
Stack은 일반적으로 할당된 메모리 영역 중 상위 주소 메모리를 먼저 사용하고 하위 주소로 커지는 방식(Top-Down)을 사용한다.
개발자는 Stack의 크기를 변경 할 수 있는데, Stack 메모리를 충분히 할당해 두지 않으면 프로그램 동작 시 할당된 Stack 영역을
초과하여 사용하게 되는 Overflow 문제가 발생 한다. Stack Overflow는 대개 전역 변수와 정적 변수가 저장되는 영역을 오염 시키며
Runtime 오류를 발생한다. 예를 들어 값이 손상된 전역 변수가 사용되거나 엉뚱한 코드를 실행하는 경우 등을 들 수 있다.
Stack의 관리
그렇다면, 나의 프로젝트에는 어느 정도의 스택이 필요할까??
적절한 크기의 Stack을 지정하고 프로그램이 문제없이 동작하기 위해서는 최대 Stack 사용량을 반영해야 하지만, 이를 어렵게 하는 많은
요소들이 있다. 먼저, SW의 구조는 점점 복잡 해지고 언제든지 인터럽트 기능이 trigger 될 수 있으며, 우선 순위에 따른 선점 관계에 있는
태스크들이 Stack 메모리를 공유하거나 또는 각각 고유의 Stack 영역을 사용 할 수도 있다. 만약 인터럽트나 태스크가 중첩되어 실행이
가능한 구조이거나 함수 포인터, 재귀 호출을 사용하여 코드를 구현했다면 최대 Stack 사용량을 계산하는 것은 더욱 어려울 수 밖에 없다.
그 밖에 Stack 사용량에 영향을 주는 요소는 컴파일러가 있다. 컴파일러는 타겟 코드를 생성하는 단계에서 함수 블록에서 사용할 Stack의
크기를 결정하는데 이는 함수의 바이너리 명령을 보면 확인 할 수 있다. 아래 main 함수의 경우 0x18 만큼의 Stack을 사용하기 위해
A10(Stack Pointer) 레지스터 값을 변경하는 코드가 존재한다.
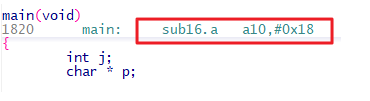
<그림> 함수 진입시 Stack 포인터를 조절하는 명령어
변경되는 Stack 포인터의 값이(위의 경우 0x18) 해당 함수의 Stack 영역이며, 이는 컴파일 최적화 옵션 설정에 따라 달라질 수 있다.
위와 같이 프로그램이 사용하는 Stack의 크기를 측정, 관리하는 것은 여러 요인에 인해 매우 어렵기 때문에 SW 개발 시작 단계에서부터
지속적으로 최대 Stack 사용량을 분석하고 관리하는 작업이 필요하다.
Stack의 크기 설정
프로그램의 Stack 사용량 분석이 완료되었다면, 이를 반영하여 Stack의 크기를 변경하는 작업은 컴파일러/링커에서 설정할 수 있다.
만약 RTOS가 적용된 개발 환경이라면 OS 설정시에 TASK/ISR 별로 별도의 Stack 영역을 각자 사용하도록 할지, 하나의 Stack을
공용으로 사용할 것 인지를 설정하고 그 크기를 지정할 수 있다.
Firmware 환경에서는 호출에 의한 함수의 중첩관계를 고려하여 최대 Stack 사용량을 정하고, OS 환경에서는 TASK/ISR 간의 선점 관계를
분석한 뒤 최대 Stack 사용량을 정할 수 있다. 즉, 적절한 Stack 메모리의 크기는 프로그램의 Worst Case Stack 사용량을 고려하여
설정해야 한다.
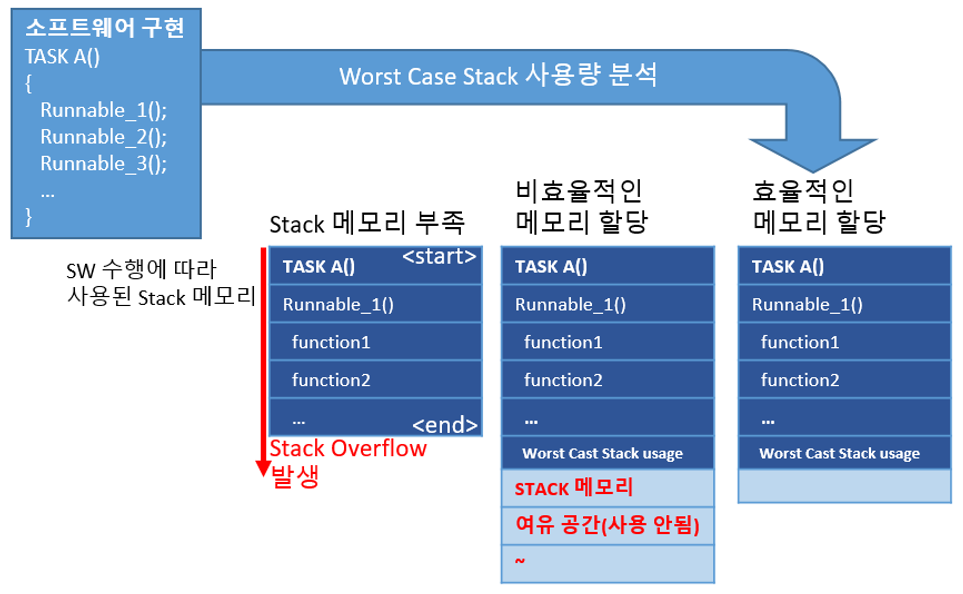
<그림> Stack 사용량 분석을 통한 효율적인 Stack 크기 할당
Worst Case Stack 사용량 분석
최적의 Stack 크기를 설정하기 위한 최대 Stack 사용량을 분석하는 방법에는 동적으로 사용량을 측정하는 방식과 정적으로 분석하는
방식이 있다. 동적 측정 방식은 최종 통합된 SW를 실 타겟 환경에서 동작하여 최대 Stack 사용량을 직접 확인하는 것이다. 이 방식은
주로 디버거를 이용하며 효율적이고 빠르게 결과를 확인 할 수 있다는 장점이 있다. 하지만 이 방식으로 측정된 최대 Stack 사용량은
Worst Case Stack 사용량이 아닐 수 있다. 테스트 환경에서 주입된 테스트 케이스에 의해 Stack 사용량이 결정되기 때문에 테스트 케이스가
Worst Case 수행 경로를 반영하지 못 할 경우 Worst Case에 대한 Stack 사용량 측정이 불가능하기 때문이다.
* 동적 측정 방식 - 테스트 시나리오
제어기 리셋 -> 대상 Stack 메모리를 특정 패턴으로 초기화 (ex – 0xA5A5A5A5) -> 제어기 동작 -> 테스트 케이스 수행 -> 모든 테스트 수행
-> 패턴이 지워지지 않는 부분을 파악하여 최대 Stack 사용량 계산
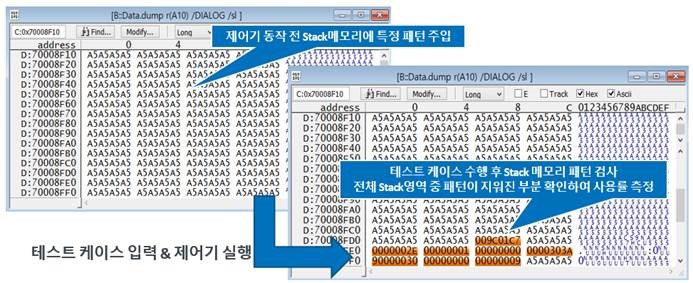
<그림> 디버거를 활용하여 동적으로 Stack 사용량 측정
동적 분석 방식의 또 다른 제약으로는 실 타겟을 기반으로 하는 통합 테스트 환경에서 코드 커버리지를 100% 만족하거나 최악의 수행 경로에
대한 테스트를 수행하기 어렵다는 점이 있다. 같은 맥락으로, 재귀함수가 사용되는 경우라면 해당 재귀함수가 Worst Case로 중첩되어 실행되는
테스트 케이스에 대한 주입도 반영하여 테스트 해야 한다. 따라서 동적 방식의 Worst case Stack 사용량 분석은 테스트 환경을 구축 하는데
많은 비용과 시간이 소요 될 수 밖에 없다. 정적 분석 방식은 바이너리 코드나 최종 실행 파일(elf) 기반으로 모든 함수 실행 경로를 분석하여
최종 Call tree를 생성하고 사용량을 측정한다.
* 정적 측정 방식 – 분석 시나리오
모든 함수의 스택 사용량 분석 -> 모든 함수의 실행 경로(Call Path)를 분석 -> 각 Call Path에서호출되는 함수들의 Stack 크기를 더함
-> 특정 함수기준의 Worst Case Stack 사용량 분석
정적 측정 방식의 장점은 다음과 같다.
- Worst Case에 대한 Stack 사용량 분석을 통해 적절한 Stack 크기를 설정 가능
- Stack 메모리 최적화가 필요한 경우 최적화 대상을 바로 확인 가능
(각각 Call path별로 Stack 사용량을 분석하기 때문)
- 함수 Call Tree 분석을 통한 SW 구조 파악 가능
** 측정 방식에 따른 Worst Case Stack 사용량 분석 결과 비교 **
대상: RTOS가 적용된 환경, TASK_10ms 함수를 대상으로 테스트
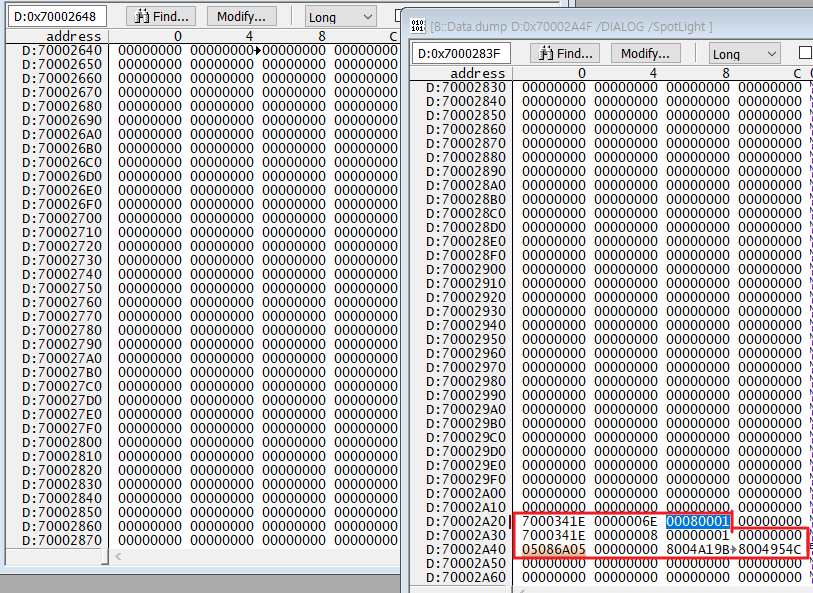
동적 측정 방식 예제
디버거를 사용하여 실제 타겟 코드를 실행 후 Stack 사용량 측정
(Ex, Task_10ms 의 전용 Stack 영역을 파악하고, 타겟 수행 후 실제 사용된 영역을 확인)

TASK_10ms 의 스택중, 0x70002A2B~0x70002AB = 0x28 만큼의 Stack이 사용된 것으로 측정
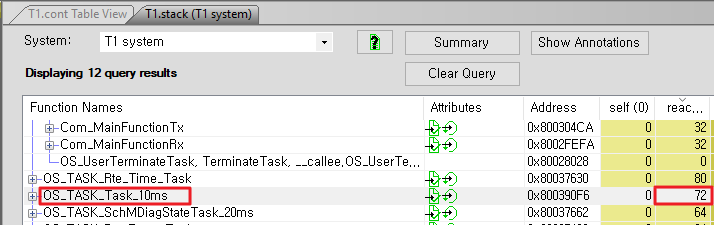
정적 분석 방식 예제
Stack 분석 솔루션을 사용하여 사용량 분석
동일한 Task_10ms 에서 0x72 만큼의 Stack이 사용될 것으로 분석되며,
이는 동적으로 측정한 방식보다 약 3배 정도 많은 Stack 사용될 수 있음을 보여줌
정적 방식으로 모든 함수의 실행 경로를 파악하려면 함수 포인터에 의한 함수 호출과 재귀함수 호출을 분석하지 않고는 정확한 Call Tree를
만들어 낼 수 없으며, Worst Case Stack 사용량에 대한 분석 결과도 정확하지 않을 수 있다. 아래와 같이 Stack 솔루션을 사용하게 되면
Stack 사용량 측정 과정에서 누락된 재귀 함수와 포인터 함수 호출의 정보를 바로 확인 할 수 있다.
T1.stack 분석 기능/결과
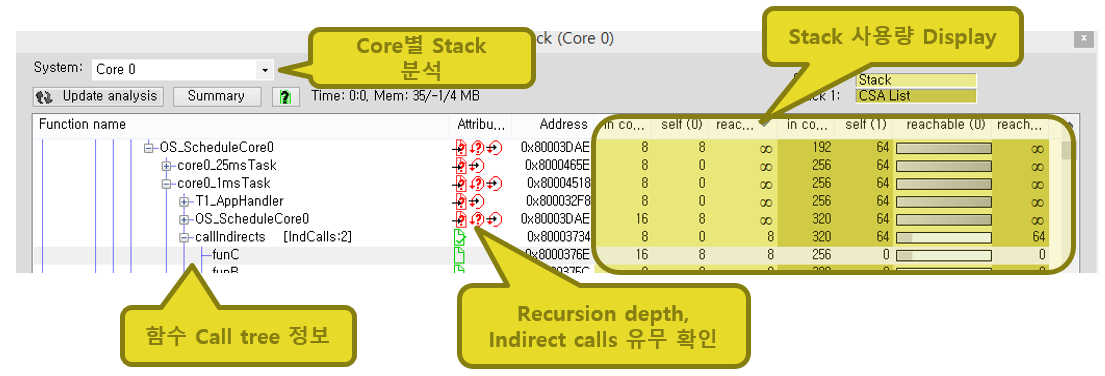
<그림> 정적 분석 방식을 활용한 Call Tree 분석 및 Stack 사용량 확인
아래 그림은 재귀 함수와 함수 포인터가 사용되는 코드를 분석하여 최종 Stack 사용량 결과를 확인하는 과정을 보여준다.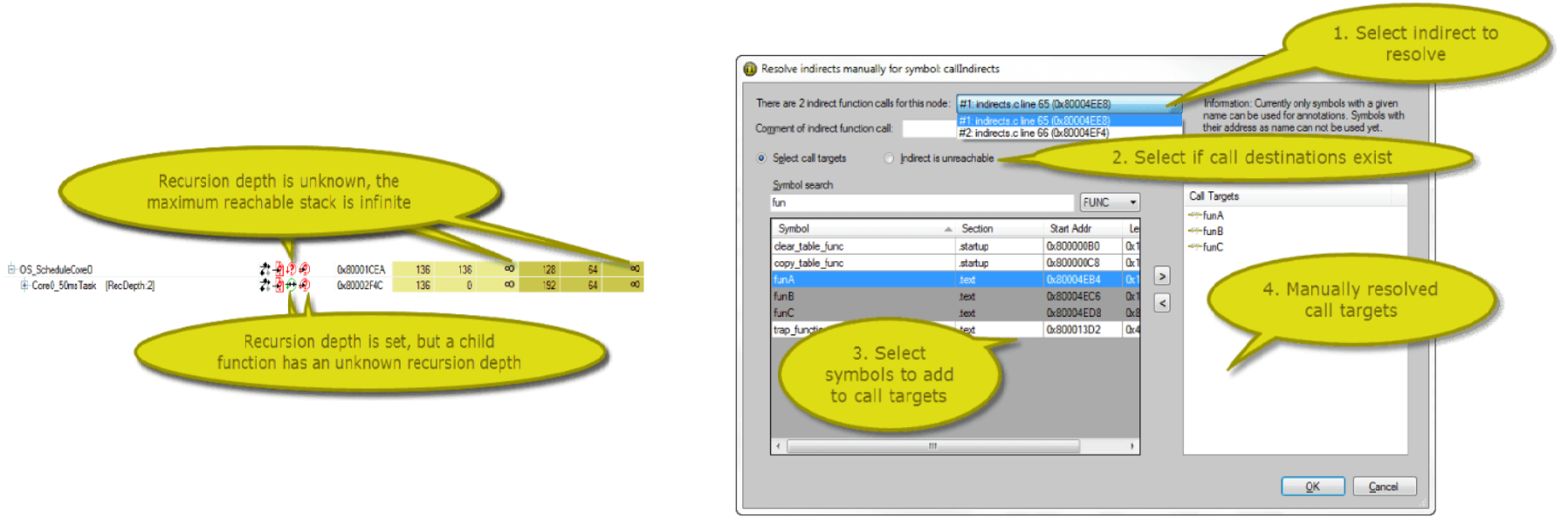
<그림> 재귀 함수의 중첩 실행 횟수 분석 <그림> 함수 포인터를 통해 호출 되는 함수 분석
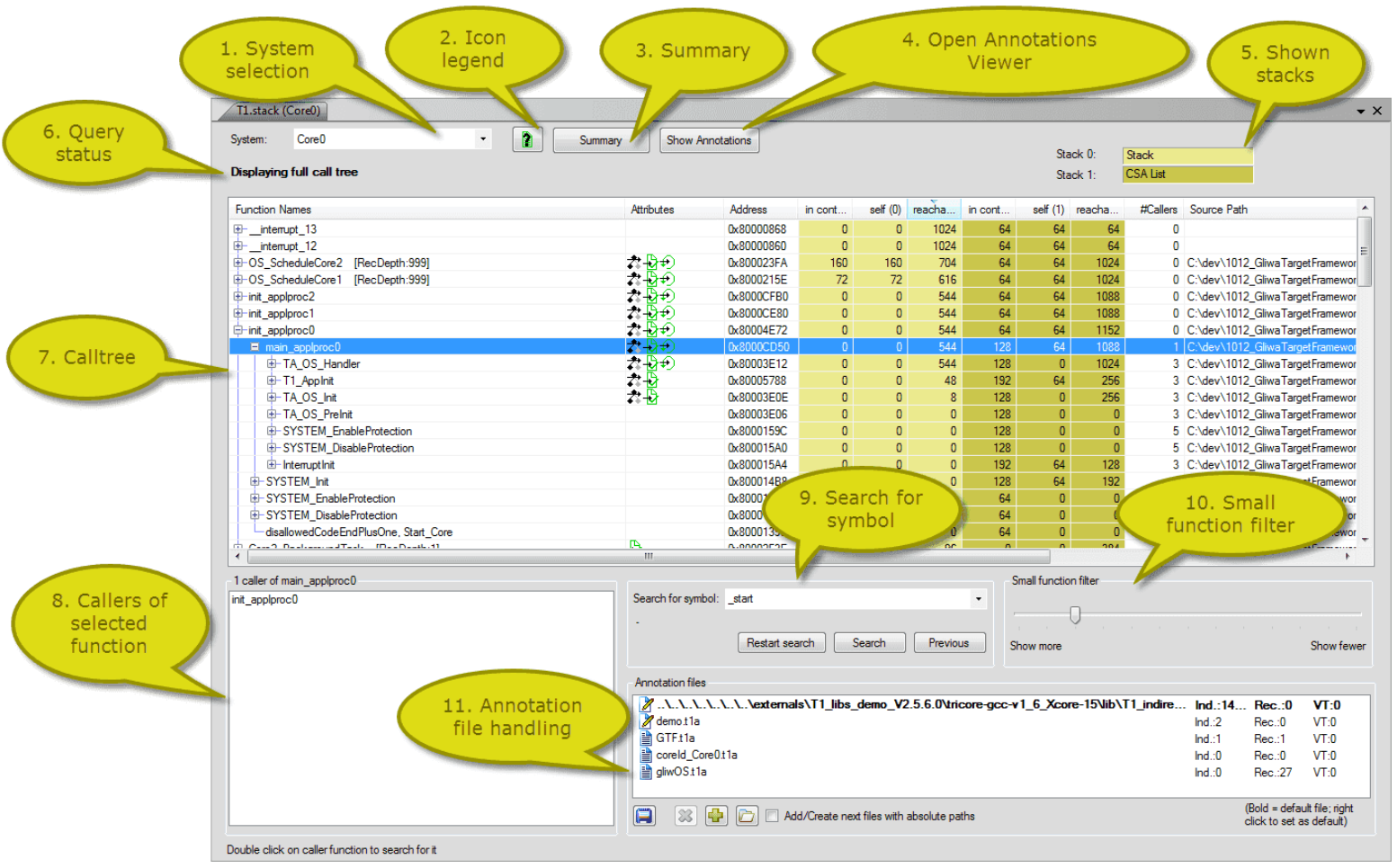
<그림> 최종 Call Tree 및 Stack 사용량 분석 완료
Run-time Stack Overflow 에러 방지
Runtime 중 Stack overflow가 발생하는 여부를 확인하는 방법은 앞에서 설명한 동적 측정 방식을 활용하면 된다. Stack 메모리의 마지막 주소에
패턴 값이 지워진 경우 모든 stack이 사용된 것으로 overflow 가 발생했음을 알 수 있다. 하지만 runtime중에는 이를 모니터링 하지 못하기 때문에
overflow로 인한 SW 오/동작을 예방 할 수 없다.
Stack overflow를 방지하기 위해서는 아래 그림과 같이 Stack의 끝 주소 다음에 일정 영역의 메모리를 접근 할 수 없도록 보호 영역을 지정해 주는
것이 하나의 방법이 될 수 있다. 또는 프로세서의 MMU나 MPU와 같은 장치를 이용하여 코드가 실행되는 도중 접근이 불가능하도록 할 수 있으며,
이 경우 특정 코드가 해당 영역에 접근하는 경우 trap이나 exception-handler를 동작시켜 예외 처리를 하도록 하면 stack overflow로 인한 SW의
오동작을 방지 할 수 있다.
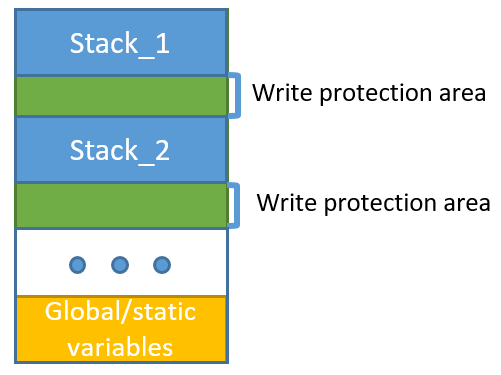
<그림> 메모리 protection을 활용한 Stack overflow 감지 방법
